
Earlier this semester, I met with a student looking for ways to easily analyze news articles and social media.
For anonymity purposes, we’ll say that Anna* was researching girl scout cookies*. Everyone loves Samoas, am I right?
Now some librarians look up a topic before a student arrives, so that they have resources ready. I don’t like doing this. Sure, I can find and present useful resources, as a gatekeeper, with a secret store of knowledge that the user and Google can’t find.
But that’s fake. I learn the same way that any professor or professional does: by trial and error.
So even as I look at background info for Anna, I’m wondering: when do students learn this? When do they learn to explore, ask around, mess around with online tool, and mess up until they get what they’re looking for?
Maybe that happens when they become research librarians. Or ‘social media experts.’ Or entrepreneurs. Or any other white-collar job focused in the fuzzy space between technology, people, and information.
That’s a long way to say that long before Anna got to my office, I was searching for text-mining tools and scrape-able news articles and social media data.
I knew I wanted something simple to use: she shouldn’t need to code, set up an API, or use specialized file formats for a class project. For now, learning to find and run data through an analysis tool (and write intelligently about the results) should be enough.
Easy Text Mining for Books: the Google nGram Viewer
I’ve mentioned Google nGrams before–a free online tool which lets you analyze the frequency of words across time and languages. But this only includes what Google Books has digitized. Here are words in close proximity to genetically modified organisms (e.g. half of what we eat, as Americans):
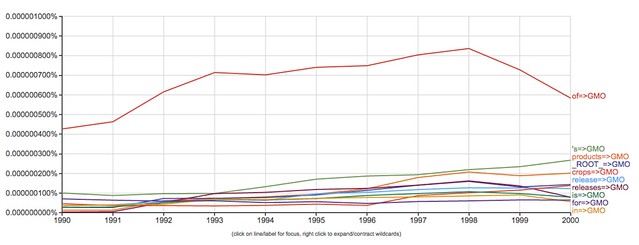
NGrams’ specialized search notation also lets you look for specific combinations of words, like nouns connected to GMOs in print books over time:
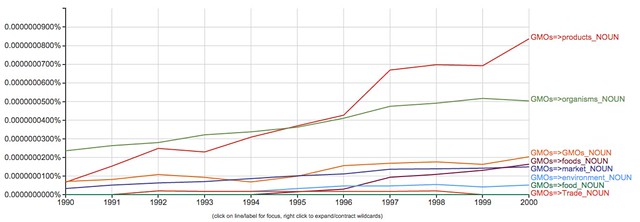
This can be a useful check on what’s written in books, but it doesn’t touch online media.
Quick Text Mining for Tweets: Topsy
Twitter is another platform that changes quickly with trends. Topsy shows what people are tweeting or blogging about, and then sharing on Twitter. I can search for ‘Kazakhstan’ by time period:

And the analytics page compares the number of tweets about each search topic, by day:
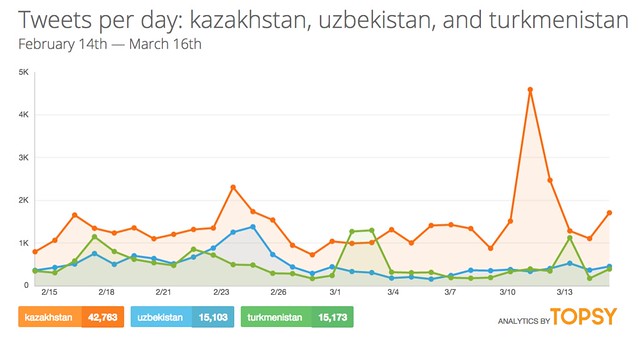
You could probably use Kimono labs or Import.io to scrape and analyze the tweets yourself… but because this just aggregates tweets, it’s kind of like a glorified search engine.
Similarly, Facebook has a mostly useless API that lets you see the technical structure of your own posts and pages. That’s revealing in itself, so check it out if tech-inclined. However, Facebook doesn’t let you search public posts or hashtags anymore. That’s yet another reason not to share data with a company that won’t share back.
Data Mining for News: The New York Times Article Search API
The NYT has an article search API that returns structured data from their news articles. You know, metadata–the information about the article (header, title, date, people mentioned):

But there’s no full-text, which doesn’t help my student.
I can search for girl scout cookies and get structured JSON data… but I haven’t studied d3.js for data visualization, so I don’t know what to do with that:
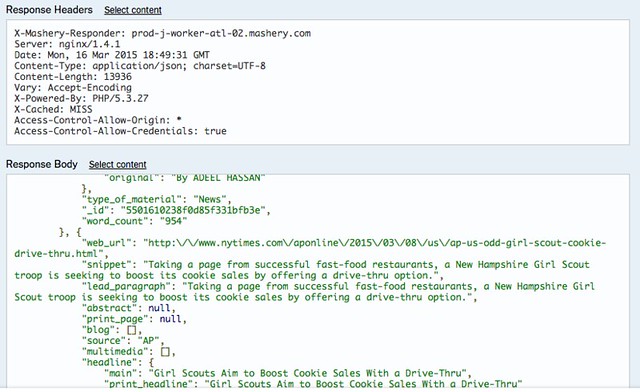
Perhaps the NYT isn’t sharing so that they can sell data at a larger price, but it’s unfortunate for students just learning to explore trends!
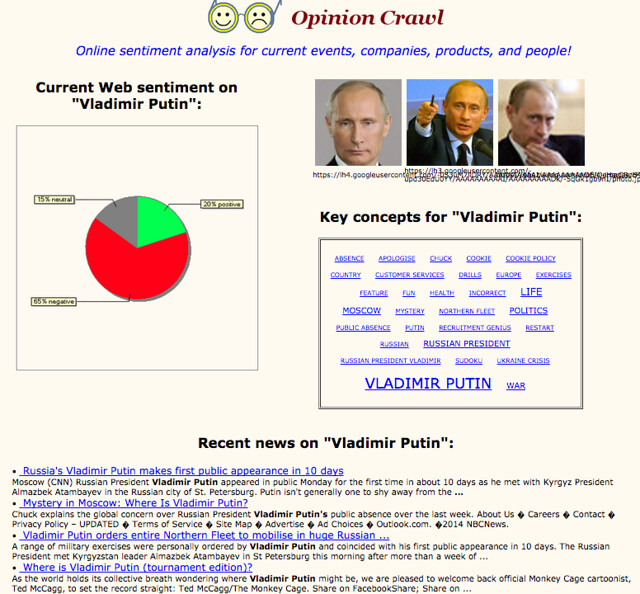
Sentiment Analysis for online chatter: Opinion Crawl
Sentiment analysis is a complex process, but Opinion Crawl gives a quick read on positive vs. negative web chatter around current events. It’s worth a quick look, but too informal for academic research:
Key Terms in Academic Articles: Data for Research (beta) on JSTOR
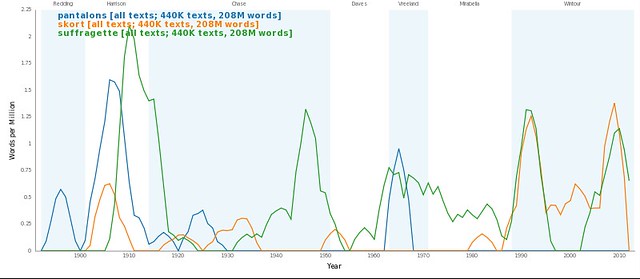
Google, Yahoo, the NYT, and Vogue have all released ways to mine their archives for topics that change over time. Below, pantalons vs skorts vs suffragettes in Vogue over time:
JSTOR
More and more libraries are negotiating with academic database providers for the right of their students to text-mine articles. JSTOR’s Data for Research (DfR) for instance, is a beta tool that lets you compare article topics over time. For instance, alongside articles on economic anthropology over the past 10 years, JSTOR provides algorithmic ‘key terms,’ which are surprisingly relevant:

I like that I can see ‘key terms’ extracted from the article rather than just the high-prestige terms the author selected. But I’m not sure what else to do with this. DfR seems underdeveloped, and is of little help to a student looking for full-text to mine.
A Source of News Articles: LexisNexis Academic
When Anna got to my office, we ended up pulling news articles on girl scout cookies from LexisNexis:
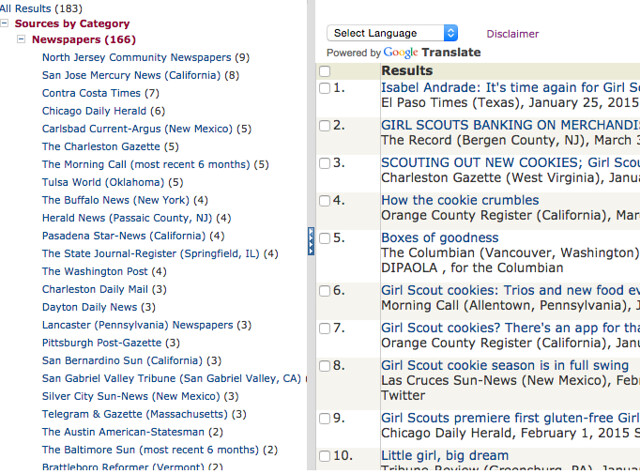
We had also tried ProQuest newspapers, but many results were in PDF and hard to copy-paste. LexisNexis, on the other hand, returned substantial full-text results, which we could narrow down by US or international newspaper, and by year of interest. Here are their results for Girl Scout Cookies in 2014-2015:
And below, a sample resulting article. This was easy to copy and paste into a text analysis program or tool:
It’s also easy, I later found, to multiselect a batch of 25-1000 articles and download them as a single text file. I can also select them one at a time and download, but that takes much more time. (However, as I’ll show below, individual .txt files are useful for analysis in the AntConc tool).

A simple textual analysis: Textalyser and ProWritingAid
I feel like I’m barely scratching the surface here, as this was my first text mining request. Anna* and I looked at discourse analysis as a textual research method, which requires close reading of a few articles (cf tutorial at Politics East Asia).
But she wanted something easier than close analysis and detailed qualitative coding (surprise, surprise). As a trial, we pasted the article from above into Textalyser, to at least get basic frequency statistics:

Like other quantitative text analysis tools, Textalyser let us compare repeated phrases of 2-5 words each, looking for common themes or topics:
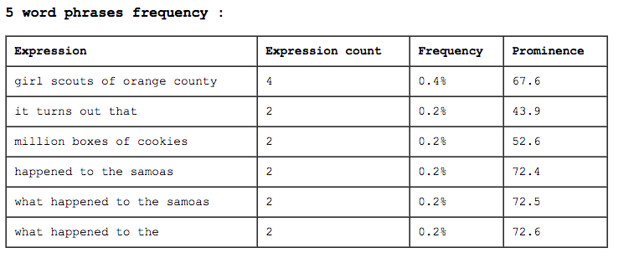
Anna was happy with this, and went to explore further on her own. I’m still not sure that Textalyser was the *best* tool, as Anna wants to analyze hundreds of newspaper articles against each other.
Another program that came to mind is ProWritingAid. It’s meant for writers, but catches repeated phrases, cliches, and awkward wording. I love it for writing, but it could perhaps be used for surface-level research as well:

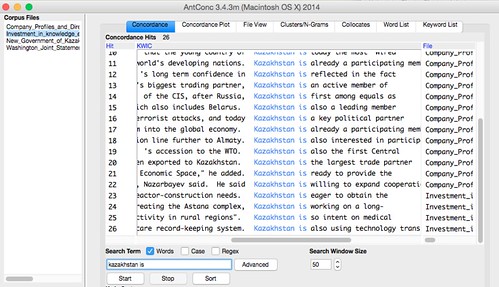
Update: After meeting with Anna, I found AntConc and related tools by Laurence Anthony. This free Windows / Mac OS X tool allows students to compare multiple files in a concordance, with word lists, keyword lists, and collocation of words. I’ll recommend it next time students ask for easy ways of of analyzing multiple texts together. (Source: Basic Text Mining intro at Macroscope).
Thoughts
I still feel like I’m learning the sources myself, as students come to me with widely disparate requests (detailed GIS points of a city in a remote country? economic indicators in 1980s Latin America? local Maine ecology and economic development?). Anna and I did end up looking at the text-analysis and digital research tools at Tapor.ca and the DiRT Directory before she left, and DiRT is where I’d recommend others start in the future to find textual analysis tools
However, I’ve shared the full process above so that you could see a couple of things:
a) how messy it is. I hit dozens of dead-end websites and tools, which I haven’t shown.
b) how variable the results. Some things above are high-quality, and others are not.
c) how complex it can be. Some tools were too intricate to learn in the 2-3 hours I allotted for exploring with and without the student.
d) How fun it can be. The tools above are open, fairly easy, and hopefully fun for you to play with and explore!